NEAR.ai → NEAR Protocol
A bit more than a year ago Alexander Skidanov and I started NEAR.ai. We strongly believed that program synthesis, the field that studies automated programming from a human specification, was going to transform software development and the world in general.

Last year at ICLR 2017 we saw a number of papers from various research labs and got really excited about the opportunity to bring that technology to the market. Both Alex and I had tried to explore program synthesis in our university days, but machine learning was so early back then that it wasn’t really possible to make progress.
After the conference, we imagined what the company would look like and realized that the first priority was to establish a benchmark for the community to use. Just as the ImageNet benchmark advanced the field of Computer Vision by leaps and bounds by giving practitioners a clear metric for comparison, we believed that a complex dataset would challenge the community as well as guide research.
We started NEAR.ai with the hypothesis that we could both expand the boundaries of research in the field of program synthesis and at the same time deliver a transformative product powered by this technology.
Alex and I have both participated in programming competitions (Alex won Gold in ACM ICPC 2008) and we naturally thought that the problems which were designed for human participants in these challenges would be a great starting point for computers doing program synthesis.
Programming competitions generate great data for machine learning. Each programming competition usually involves solving 5–10 problems of increasing difficulty stated in natural language. Problems are then solved by participants in various programming languages, producing the “parallel corpus” of description — code pairs.
Over a year, we collected more than 30k+ problems and 10M+ solutions. Many of the problems were hard even for a regular software engineer to solve, so we focused on problems that are simple (e.g. A and B on CodeForces or 250 on TopCoder). Even then, the task descriptions were complex: the variety of concepts and language used in the descriptions were too much for the model to capture. Furthermore, some problems required logical reasoning steps and external mathematical knowledge. To simplify the first task, we crowdsourced to the CodeForces community to rewrite the descriptions of the problems into a “solution description”.
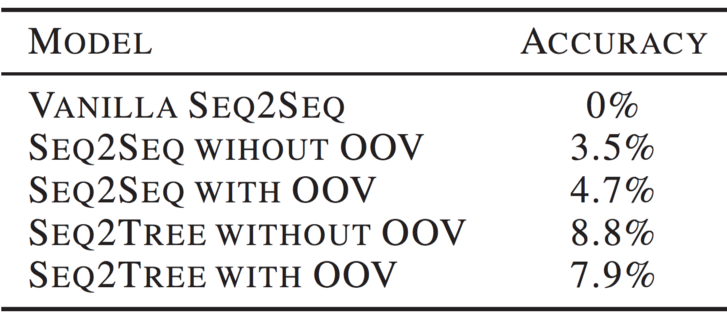
We published part of the dataset we collected in our ICML 2018 paper “NAPS: Natural Program Synthesis dataset”. However, despite all this work and after running state-of-the-art models (which combined deep learning and regular search techniques) on this dataset , we found that results were far from usable in practice (around 12% for our best model).
Alongside the technical work, we gathered feedback from prospective users to make sure there was a real demand in the market for our solution. We built prototypes (without any ML) and tested the experience using Wizard-of-OZ (or human-in-the-loop) model.
After several iterations of this, we realized that ML, specifically natural language understanding, is not there yet.
Meanwhile, there were a few ideas that lead to our transition:
- Given our work in program synthesis, our advisors suggested looking into the field of generating smart contracts for Ethereum. At the moment, it’s hard to program provable contracts for a regular engineer, an issue that can be effectively addressed by program synthesis.
- The more we spoke with people who want to build applications, the more buzz we heard about building apps using blockchain to provide monetary incentives and better privacy & security.
We sat down with our friends David “Pieguy” Stolp and Evgeny Kuzyakov, who have been playing with blockchain on the side over last year to learn more about this space. As we dug deeper into the rabbit hole, we realized both the opportunity and the limitations of the current blockchain systems.
For developers, blockchain provides the infrastructure that currently requires months to setup: partition resilient networking, always available database and compute, ease of GDPR compliance, and reduced need in local regulatory compliance. Additionally, entrepreneurs can come up with entirely new business models for businesses built on top of the blockchain.
For users, blockchain ensures data privacy and security. The smart contracts provide guarantees and can be studied (probably not by the user, but news about the malicious contract would spread really fast while data leaks in walled gardens can be covered up).
On the other hand, there is a reason why currently new applications are not built on the blockchain. Ethereum, the most popular decentralized app platform currently, has 14 transactions per second worldwide. I repeat, 14 API calls per second worldwide, the big part of which is taken by exchanges and speculative trading, making it more complicated to use. As a result, each transaction takes from minutes to hours to actually make it into the ledger.
There are newer protocols that suppose to fix the problem with the performance of blockchain:
- EOS — recently launched and had one of the largest ICOs, but at the end uses 21 people to sign the blocks, meaning that these 21 people decide on how ledger will be composed. They know each other and have a huge monetary incentive to not slash for bad behavior, even when they had already approved “double spends” or if they decide to rewrite history.
- IOTA — great idea from the distance: no blocks, each IOT device can post transactions and they get confirmed by others posting transactions. The problem lies in details : each node must do 5 minutes of proof of work to post the transactions (or they would spam it), which means that finality is >5 minutes. Additionally, each IOT device should maintain a huge part of the DAG that has been built or it will be easily tricked into approving “double spends”, which prevents the protocol from running on real IOT devices. To make things worse, there is Coordinator, a centrally maintained checkpointing system to prevent long-range attacks.
There are other protocols, many of which are still building their tech, but each and every one of them is missing a conceptual thing. All the successful platforms started by bringing developers closer to users, instead of building better tools for developers.
This is what gave birth to NEAR protocol:
- Allow developers to build blockchain native mobile dApps and run it where the users are (mobile phones), giving developers a key onramp into dApps
- Through sharding by state, allow the blockchain to scale linearly with the number of nodes in a network (we are targeting ~100k tps @ 1 million mobile nodes)
- Allow blockchain entrepreneurs to quickly iterate and come up with successful business models since they both have scalable blockchain and easy access to users via first mobile-native blockchain
In other words: NEAR is a fully sharded, proof-of-stake blockchain that is specifically designed so mobile phones can fully participate from day 1.
To achieve this, we are redesigning every component of the protocol, from networking to consensus to sharding the state and execution to how user client works. You can read our first position paper and stay tuned for more: we will release sharding and consensus technical papers next.
We got together a dream team of builders: 3 ICPC Gold medallist (Mikhail was 2-time world champion), 3 early MemSQL (built sharding for the distributed database), 4 Xooglers (built distributed systems at scale).
Over the next several weeks, we will be sharing technical details, how we are thinking about the blockchain space and applications we believe our protocol will unlock.
To follow our progress you can use:
- Twitter — https://twitter.com/nearprotocol,
- Medium — https://medium.com/nearprotocol,
- Telegram — http://t.me/cryptonear,
Lastly,
https://upscri.be/633436/
Thanks to Alexander Skidanov, Maksym Zavershynskyi, Erik Trautman, Aliaksandr Hudzilin, Bowen Wang for helping to put together this post.
Share this:
Join the community:
Follow NEAR:
More posts from our blog

NEAR Launches Infrastructure Committee with $4 Million in Funding

